NTFS结构略解——教你自己解析NTFS文件系统
一、前言
NTFS(New Technology File System)是微软开发的专用文件系统,是 Windows 默认使用的文件系统,使用数量非常巨大。但是 NTFS 的技术细节是不公开的,所以想要自己解析这个文件系统还是有一定的难度。所幸目前已经有许多关于 NTFS 结构的教程,所以要学习 NTFS 也不是完全没有门道。这篇文章就在前人工作的基础上,结合具体的磁盘数据来解读 NTFS 的结构,从解析分区表开始教大家一步一步还原一个磁盘镜像中的 NTFS 文件。
需要指出的是,下文中所有文件结构的解析都和实际镜像分析结合在一起呈现。这样的好处是便于读者比较着本文自己动手实践,但是有关结构的呈现可能不如直接列表直观,需要在阅读的时候多进行联想和猜测。同时也鼓励读者自己制作一个 Windows 镜像,然后尝试还原出镜像中某个文件的数据,这个过程对掌握 NTFS 结构的帮助是巨大的。本文的实际镜像分析都来自于同一个 Windows 10 镜像,由于 NTFS 向前和向后兼容性很强,因此不同版本的系统可能存在不同之处。此外 NTFS 系统体量庞大,细节颇多,疏漏之处还请谅解。
二、前置知识
这部分知识与 NTFS 没有直接的关系,但是对你在一个磁盘镜像里找到 NTFS 分区是很有帮助的。
扇区
在机械盘中,数据储存在圆形的磁盘上,按同心圆一圈一圈排列,每一圈就叫一个磁道。为了加快运行速度,机械盘把每个磁道等间隔地划分成若干个区域,以一个区域为单元读写数据。由于这个区域在圆形磁道上长得很像扇子,就被称为扇区。到了固态盘时代,虽然不再用圆形磁盘来存取数据了,但仍然需要以某个固定长度的数据为单元操作数据,并且仍然沿用扇区的概念。
虽然苹果公司警告你最好不要这么做,但一般来说,我们可以认为扇区的大小都是 512 字节。
在机械盘普遍使用的时候,通常使用 CHS(cylinders-heads-sectors ,磁柱-磁头-扇区)模式来定位一个扇区。但是在固态盘中并不存在磁头和磁柱的概念,并且扇区数更多,所以就采用更单纯的寻址模式:从 0 开始编号每一个区快。这样的编号就称为 LBA(Logical Block Address ,逻辑区块地址)。例如 LBA0 指的就是磁盘的第一个扇区。
主引导扇区
MBR(Master Boot Record ,主引导扇区)一般是磁盘的首个扇区,也是开机后读取的首个扇区。这里包含磁盘的引导程序以及磁盘分区表,我们关注分区表就行了。
下面是一个磁盘的 MBR 分区数据以及解析:
1 | ---- LBA0 ---- |
可以看到这个磁盘采用的是 GPT 分区,所以主引导扇区里没有分区表。目前 NTFS 常用的是 MBR 分区表和 GPT 分区表,本文就只介绍这两种。
- MBR 分区表
MBR 分区表和主引导扇区名字一样,因为这个表是直接放在 MBR 里的。但是可以看到 LBA0 的空间很有限,采用 MBR 分区就只能拥有 4 个分区,所以现在很少用。此外还有 MBR/GPT 混合分区,会把 GPT 分区的前 4 个分区放在 MBR 里。如果是纯 GPT 分区则只有一个标识为 0xEE 的分区。
- GPT 分区表
GPT(GUID Partition Table ,全局唯一标识分区表)又叫 GUID 磁碟分割表,它占用一个 LBA 作为分区表头,记录分区表项的信息,然后接下来的若干个 LBA 储存分区表项。
下面是一个磁盘的 GPT 分区表头和表项:
1 | ---- LBA1 ---- |
从分区表头可以找到分区表项的起始 LBA ,然后在 LBA2 中就可以读到第一个分区的起始位置和结束位置了。在这个磁盘中,第一个 GPT 分区并不是 NTFS 分区(一般都不是),第三个分区名为 Basic data partition 的分区才是。根据起始 LBA 就可以计算出 NTFS 分区的起始地址为 0x3A800 * 512 = 0x7500000 。
三、分区引导扇区、主文件表和元文件
分区引导扇区是 NTFS 的第一个扇区,包含了一条 JMP 指令、NTFS 标识符、本 NTFS 文件系统的基本信息和启动指令。
下面是一个 NTFS 分区引导扇区:
1 | 07500000 - EB 52 90 4E # 分区引导扇区 |
这里边有很多有用的信息。第一个信息和 NTFS 中的特有概念“簇”有关。
簇
和磁盘将扇区作为存取单元一样,为了使系统运行更高效,NTFS 有自己的存取单元,叫做“簇”。一簇通常由若干个扇区组成,每簇扇区数可以直接从分区引导扇区读出。家用个人电脑的簇大小往往是 8 个扇区,这时 NTFS 的存储单元大小就是 8 * 512 = 4096 字节,这就是传说中的 4k 扇区。
簇的存在产生了两个名字很相似的概念:文件的分配大小和实际大小。如果你创建一个只有 1 个字符的 txt 文档,然后查看它的大小,那么你会惊喜地发现这个 txt 的大小为 4Kb 。因为存储的最小单元是 4k 字节,所以不到 4k 的部分只能空置了。这时我们就说这个 txt 的分配大小是 4Kb ,但实际大小只有 1b 。这样做虽然浪费了一定的空间,但好处是大块的存取会更高效,因此 4k 扇区是一个权衡之后的选择。
与簇相关的概念还有 LCN(Logical Cluster Number ,逻辑簇号)和 VCN(Virtual Cluster Number ,虚拟簇号)。它们分别表示在整个卷中的簇号和在文件内部的簇号。VCN 在磁盘上不一定是连续的,它们可以被映射到任意 LCN 上。
获取了簇大小之后,我们的关注点来到第二个信息:MFT 的簇号。根据这个簇号就可以定位 MFT ,也就是主文件表的地址。
主文件表
MFT(Master File Table ,主文件表)自身也是一个文件,它储存了文件系统中所有文件的属性。想要访问一个文件的内容,就要先找到文件在主文件表中的位置,然后再定位到储存这个文件数据的地方。
MFT 中的表项被称为文件记录,每个文件可能占用一个或者多个文件记录。每条记录的大小都相同,大小规定在分区引导扇区中,并且记录在磁盘上连续、紧凑而且有序地排列。例如之前的分区引导扇区表示一个文件记录大小为 1024 字节,那么 0xC7500000 - 0xC7500400 就是第一条文件记录,而 0xC7500400 - 0xC7500800 就是第二条。如果知道了一个文件在 MFT 中的标号,那么就可以通过计算定位文件记录的位置。MFT 作为一个文件,它的文件记录也包含在 MFT 表中,并且总是在第 1 个(标号为 0)。MFT 起始地址开始的两个扇区就是 MFT 的文件记录。
元文件
事实上,包括 MFT 在内,主文件表中的前 16 个文件通常是固定的,这些文件全部都以“$”开头,并且大多不对文件系统的客户端可见(根目录除外)。它们是用于定义和组织文件系统的特殊文件,被称为元文件。所以 MFT 在文件系统中的名字其实是“$MFT”。
元文件虽然有 16 个,但是如果只是读取 NTFS 系统中的某个文件的话,它们大多是没有用的。需要关注的只有编号为 0 的“$MFT”和编号为 5 的根目录“$Root”。
四、文件记录
要进一步解析 MFT 和根目录,就要详细了解 NTFS 储存文件数据的方式。
文件头
NTFS 中的文件记录由一个文件头和若干条文件属性组成。文件头记录的信息很有限,文件名、文件大小等重要的属性还是要从文件属性条目中获取。但是为了方便读者自己实践,这里还是以 MFT 为例给出文件头的结构:
1 | C7500000 - 46 49 4C 45 # FILE,但是$MFT |
其中更新序列号与一个扇区最后的 2 个字节有关。NTFS 所有记录型的数据都是 512 字节对齐的,并在每 512 字节的末尾 2 字节写入一个校验值,以确保所有数据都被正确写入到磁盘中。但如果最后两字节也要记录数据,要记录的数据就写在更新数组中,而原来的末尾 2 字节仍然记录序列号。这里一个文件记录包含 2 个扇区,所以更新数组长度为 4 ,要分别记录两个扇区的末 2 个字节,而更新序列号的两字节会同时出现在第 1 和第 2 扇区末尾。但同时也可以看到更新数组为 0 ,说明没有往最后 2 字节写入数据,不用替换序列号。
其余我们主要关心两条:0x14 开始的两个字节,表示第一个属性的偏移地址;以及 0x16 开始的两个字节,表示这个文件是否是目录以及是否被删除。根据第一个属性的偏移地址就可以定位到第一条属性。文件属性也是相邻排列的,要想遍历每一个属性,就要根据当前属性的偏移和长度计算出下一个属性的偏移。属性的偏移地址一定是 8 对齐的,如果长度不是 8 的整数倍就在最后补 0 。补 0 的部分也会算在属性长度内。
文件属性
一条文件属性又由属性头和属性体组成。不难理解,属性头记录文件属性的重要信息,包括属性类型、属性名、属性长度、属性体开始的偏移、以及是否为常驻属性等。什么叫常驻属性呢?有些类型的文件属性(如文件数据,子文件夹列表)内容太大,没法直接放在 MFT 里,因此需要链接到其他空间储存,这种就叫做非常驻属性,而将属性内容完全放在文件属性里的属性就叫做常驻属性。常驻属性和非常驻属性的文件头结构是不一样的,这里一定要注意。
下面是一个常驻属性的属性头结构:
1 | 00 04 | 10 00 00 00 # 属性类型 |
下面是一个非常驻属性的属性头结构:
1 | 非常驻属性的属性头和常驻属性不一样 |
实践中务必注意区分常驻属性和非常驻属性的文件头。
文件属性的种类标志着文件属性的意义,也决定着文件属性的结构。下表是常见的文件属性及其意义:
(参考自罗文华《电子物证技术基础》)
| 属性类型 | 属性名 | 属性描述 |
|---|---|---|
| 10 00 00 00 | $STANDARD_INFORMATION | 标准信息,包括创建时间、是否只读等基本属性 |
| 20 00 00 00 | $ATTRIBUTE_LIST | 属性列表,当一个文件需要使用多个 MFT 文件记录时表示该文件的属性列表 |
| 30 00 00 00 | $SFILE_NAME | 文件名 |
| 40 00 00 00 | $VOLUME_VERSION | 在早期的 NTFS v1.2 中为卷版本 |
| 50 00 00 00 | $SECURITY_DESCRIPTOR | 安全描述符,Windows 2000 已将安全描述符放在 $Secure 元文件中 |
| 60 00 00 00 | $VOLUME_NAME | 卷名,仅存在于 $Volume 元文件中 |
| 70 00 00 00 | $VOLUME_INFORMATION | 卷信息,仅存在于 $Volume 元文件中 |
| 80 00 00 00 | $DATA | 文件数据 |
| 90 00 00 00 | $INDEX_ROOT | 索引根 |
| A0 00 00 00 | $INDEX_ALLOCATION | 索引分配 |
| B0 00 00 00 | $BITMAP | 位图 |
| C0 00 00 00 | $SYMBOLIC_LINK | 符号链接 |
| D0 00 00 00 | $EA_INFORMATION | 扩充属性信息,现已使用不多 |
| E0 00 00 00 | $EA | 扩充属性,现已使用不多 |
| F0 00 00 00 | $PROPERTY_SET | 早期的 NTFS v1.2 才有 |
| 00 10 00 00 | $LOGGED_UTILITY_STREAM | EFS 加密属性,主要存储 EFS 有关的加密信息,如解码密钥等 |
此外还有很多其他属性,限于篇幅就不列了。这些属性中最常用的是 10H 、30H 、80H 、90H 和 A0H 属性,其他的功能也很强大,但是我们只读取一个文件的话就用不到了。下面重点分析这些最常用的属性。
10H 属性
下面是一个 10H 属性体:
1 | 10H属性体: |
10H 属性比较简单,我们主要关心时间属性和传统文件属性。
- 时间属性
首先来看时间属性,四个时间的含义和名称相同,不用再解读了。但特别要强调的是,这里的时间不是 Unix 时间戳,而是 Windows 特有的 FILETIME 时间戳。FILETIME 与 Unix 时间戳的区别在于 FILETIME 是从 1601-01-01 00:00:00 开始的,这个时间比 Unix 时间戳早了 11644473600 秒;同时 FILETIME 的计时单位是 100 纳秒,而不是 1 秒。因此其实可以通过一个很简单的公式来把 FILETIME 转化成 Unix 时间戳:
1 | unix_time = (unsigned)(windows_time / 10000000 - 11644473600LL) |
得到 Unix 时间戳后再用各种语言的内置库转化为需要的时间格式就很容易了。
- 传统文件属性
传统文件属性用来标志只读、临时、压缩、加密等特种文件。如果传统文件属性的某一个二进制位为 1 ,则表示这个文件属于对应的特殊类型。文件属性的含义表格如下:
| 标志 | 二进制位 | 含义 |
|---|---|---|
| 0x0001 | 0000 0000 0000 0001 | 只读 |
| 0x0002 | 0000 0000 0000 0010 | 隐含 |
| 0x0004 | 0000 0000 0000 0100 | 系统 |
| 0x0020 | 0000 0000 0010 0000 | 存档 |
| 0x0040 | 0000 0000 0100 0000 | 设备 |
| 0x0080 | 0000 0000 1000 0000 | 常规 |
| 0x0100 | 0000 0001 0000 0000 | 临时 |
| 0x0200 | 0000 0010 0000 0000 | 稀疏文件 |
| 0x0400 | 0000 0100 0000 0000 | 重解析点 |
| 0x0800 | 0000 1000 0000 0000 | 压缩 |
| 0x1000 | 0001 0000 0000 0000 | 脱机 |
| 0x2000 | 0010 0000 0000 0000 | 未编入索引 |
| 0x4000 | 0100 0000 0000 0000 | 加密 |
可以看到 10H 属性的例子中,传统文件属性为 0x0006(06 00 ,注意是小端序),表明这是一个系统文件,而且是隐含的。这与 MFT 文件的定位相符。
30H 属性
30H 主要用来储存文件名,但其实也包含时间属性、传统文件属性和文件大小。下面是一个 30H 属性体:
1 | 30H属性体: |
这里需要注意的是文件名的命名空间。在早期的 FAT 系统(MS-DOS 使用)中是不支持长文件名的,采用的是 8.3 命名规范。NTFS 支持使用 Unicode 字符表示的长文件名,但为了兼容,会生成一个备用的 MS-DOS 文件名。这个备用文件名是根据原文件名以一定规则转换得到。所以一个文件可能会有多个文件名属性。此外,还会存在一个文件拥有两个文件记录,文件名分别为长文件名和短文件名的情况。因此如果你想要写一个 NTFS 解析系统,这一点是需要特别处理的。
80H 属性
80H 是一个非常驻属性。前面说过,非常驻属性的属性体并不在文件记录内,而是链接到了其他地方,记录这个链接的机制就叫做 Run List 。一个 Run List 条目记录一条 Data Run(数据运行)信息,所谓 Data Run 就是指异地存储的数据。条目由 3 部分组成:长度、占用簇数和起始簇号。
- 长度
Run List 将占用簇数和起始簇号压缩在一个字节内来表示一条 Run List 的长度。其中高 4 位为起始簇号的长度 N ,低 4 位为占用簇数的长度 L ,这个 Run List 条目的总长度就是 1 + L + N 。
- 占用簇数
长度之后有 L 个字节表示对应 Data Run 占用的簇数。
- 起始簇号
起始簇号的机制比较复杂。第一个 Data Run 的这个值就是它的起始簇号,但是从第二个开始就变为相对于上一个 Data Run 的变化量,并且这个变化量是有符号值。从另一个角度也可以理解为所有的这个值都表示相对于上一个的变化量,但一开始这个基数是 0 ,那么第一个 Data Run 的起始簇号是 0 + 这个值。
下面是一个 80H 的 Run List:
1 | 00 01 | 32 # 高4位为起始簇号长度为N,低4位为占用簇数长度为L |
这个 80H 是属于 MFT 的,可以看到起始簇号 0xC0000 就是 MFT 的起始簇号。
严格意义上来讲,Run List 并不算属性体,实际上的属性体应该是 Run List 指向的 Data Run 。只不过 80H 的属性体没有任何结构,直接就是储存的文件数据,但某些属性是可能在 Data Run 里还有结构的。
五、索引
90H 和 A0H 属性都是为索引服务。索引的结构比较复杂,所以需要新的一节来专门解释。
NTFS 的索引结构是 B+ 树,我们读取文件的话不需要考虑 B+ 树的节点限制,只需要进行树结构遍历就可以了,不过 B+ 树的结构还是需要有所了解。简单来说,B+ 树由若干个单链表组成,每个链表中的节点都是一个树节点。每个树节点最多有一个子节点,而这个子节点一定是另一个链表的链头。用图像来表示就是这样:
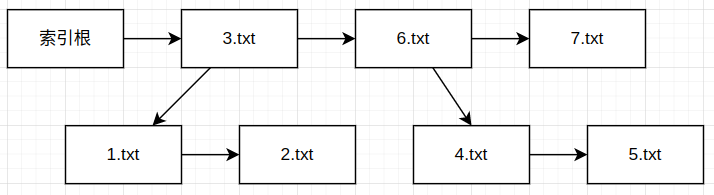
因此每个节点都可能有一个下一个节点和一个子节点。NTFS 中的索引是有序的,如果是大索引,那么一个节点的文件名一定大于子节点的文件名,通过这个特点可以加速文件查找。例如当前节点文件名为 3.txt ,下一节点为 6.txt ,而查找的目标是 4.txt 的话,就可以跳过 3.txt 去遍历 6.txt 的子节点。
90H 属性
90H 是索引根,是一个常驻属性。这里的索引指的是对文件的索引,一般是文件夹会有这个属性,用来表示文件夹内的文件。索引根只是一个提供索引基本信息的东西,经常和 A0H 索引项属性一起出现,但 90H 里也会储存一些索引项,有时干脆没有 A0H 属性。
下面是一个 90H 属性体:
1 | 90H属性体: |
90H 属性体由 2 部分组成:索引根和索引项。
- 索引根
索引根是 B+ 数的入口,包含了 B+ 数的一些基本信息,如是小索引还是大索引,以及最关键的索引项的入口。
- 索引项
每个索引项都是一个 B+ 树节点。虽然按照 B+ 树的定义,非叶子节点不应该有数据,但是在 NTFS 里好像每一个索引项都表示一个文件。
下面是一个装有非空索引项的 90H 属性体:
1 | 索引根: |
这里的索引项就表示了一个文件,记录了文件的 MFT 参考号、时间属性、文件名等。而且例子中的索引项索引标志为 0 ,表示没有子节点,并且还有下一项。如果索引项有子节点,那么就要用子节点索引所在 VCN 找到子节点(VCN 是虚拟簇号,在前面有过介绍)。如果有下一项,那么下一项应该紧挨在这一项之后。
A0H 属性
A0H 是索引分配,是一个非常驻属性,在文件记录中只保存了 Run List ,所以我们直接分析 Data Run 储存的属性体。
下面是一个 A0H 的属性体:
1 | C7524000 # 49 4E 44 58 # INDEX |
可以看到 A0H 的属性体和 90H 差别不大,也是由索引头和索引项组成,只不过是内容较大,所以进行了异地储存。此外还多了“INDEX”标识、更新序列号等信息。
六、总结
至此,你已经可以自己拿着一个 NTFS 镜像去恢复某个文件了。恢复的过程大概遵循如下步骤:
-
在 MBR 查看分区表,并找到 NTFS 分区起始位置
-
读取簇大小等属性
-
根据 MFT 簇号计算 MFT 的起始位置并记录
-
根据根目录的 MFT 号(一定为 5 )计算根目录的文件记录的起始位置
-
解析文件头,找到第一个属性的入口
-
遍历每一个属性,找到 90H 属性和 10H 属性
-
遍历 B+ 树结构,找到下一层文件的 MFT 号
-
根据 MFT 号计算此文件记录的起始位置
-
重复 5 - 8 ,直到找到要还原的文件
-
解析 80H 属性,还原出文件数据
上述步骤虽然多,但是只要能从头到尾做一遍,基本就能将 NTFS 的基本结构掌握在心中了。除此之外还有一些细节问题,如某些扇区可能需要替换更新序列号、某些属性计算偏移时要考虑属性名长度等,这就留待读者朋友在实践中总结了。